Web Crawler/Spider ve Scrapy
Web Crawler Nedir?
- Crawl kelimesi “emeklemek, yavaş ilerlemek” anlamına gelmektedir. Belirli bir hedefe, amaca ulaşmak için yapılan bir takım işlemlerdir.
Web Crawler Nasıl Ortaya Çıktı?
- Web crawler arama motorlarının doğuşu ile beraber ortaya çıktı. Arama motorlarının internet üzerinden linkleri toplayıp, indexleyip, insanların bilgiye doğru ve hızlı bir şekilde ulaşmasını amaçlamışlar. Kısaca linkleri izlemek ve bilgi toplamak amacıyla ortaya çıkıyor.

Neden Crawler ve Spider isimleri verilmiş?
- Aslında yukarıda da söylediğim gibi belirli zaman aralıklarıyla sürekli olarak aynı işlemlerin tekrarlanması(linklerin izlenmesi), crawl kelimesinin bebeklerin ve sürüngenlerin hedefe ulaşmak için yaptıkları bir takım işlemlere benzetilmesi, linklerin izlenmesi ve ağ yapısının büyümesinin örümceklerin ağ örmesine benzetilmesidir.

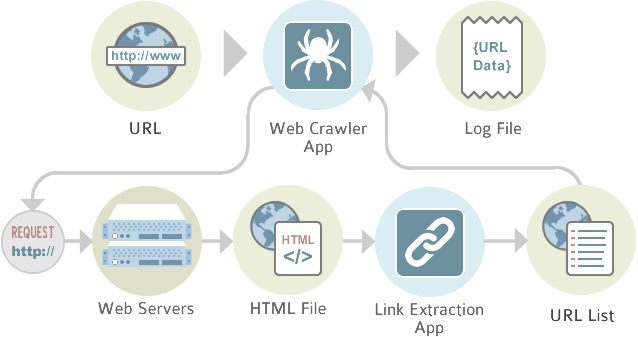
Web Crawler Basit Çalışma Mantığı Nasıldır?
- Web sayfalarını indir
- Bağlantıları çıkar
- Anahtar kelimeleri çıkar
- Kelime ve sayfa bilgisini indexer geçir
- Bulunduğun bağlantıdan devam et ve aynı adımları tekrarla.
Web Crawler Basit Çalışma Mantığı
- Web Crawler kendi içinde kategorilere ayrılmaktadır. Şimdilik sadece isimlerini vermek ile yetineceğim ve bu kısımları scrapy ile bir uygulama yazarken ihtiyaçlar dahilinde nasıl kullandığını göstereceğim. Bunlar; DeepCrawl, Full Body Text, Meta Robot Tag, Frame Support, Meta Description, Stop Words, Robots.txt, Meta Keywords gibi..
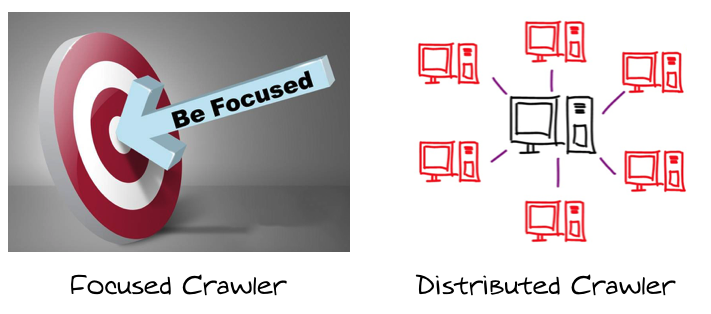
Web Crawler Kavramları Nelerdir?
- Kavramlar konusu genişletilebilir fakat genel olarak en çok kullanılan 2 konsept var. Focused Crawler ve Distributed Crawler
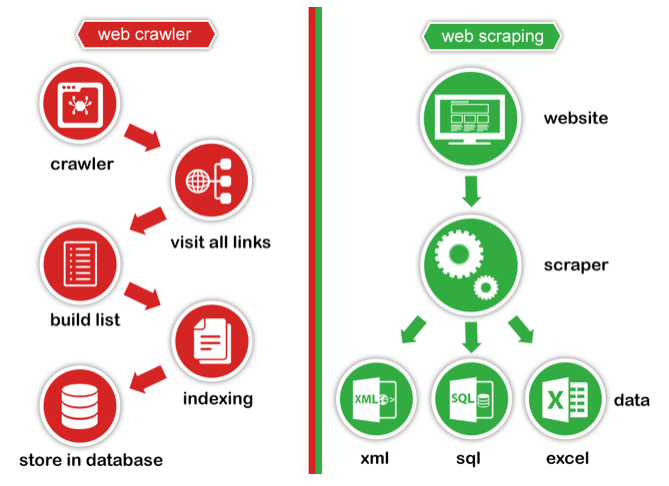
Web Crawler vs Web Scraping
- Kısaca web crawler linkleri izlemek, listelemek, indekslemektir. Google, Yandex, Yahoo, Bing gibi arama motorlarının sitelere gönderdikleri örümcekler, botlar gibi…
- Web Scraping ise kişinin isteğine bağlı olarak belirli bilgilerin toplanması ve işlenmesidir.
Web Crawling/Scraping Legal mi?
-
Web crawling yasal bir olaydır. İllegal olan kısmı dataların toplanması değil, toplandıktan sonra analiz etmek, datayı anlamlandırmak ve kurumlara satılmasıdır. Bunun dışında bilgi toplarken dikkat etmemiz gereken kurallar vardır.
-
Web crawling doğru şekilde yapılmadığı sürece engellenebilirsiniz daha kötüsü karşı tarafı çökertebilirsiniz. Bir çeşit DDOS saldırı yapabilirsiniz. Bununla ilgili olarak şöyle bir resim paylaşacağım. Altına ufak bir açıklama geçeceğim ve konuyu daha fazla uzatmadan Scrapy kullanımını ve mimarisini anlatmaya başlayacağım.
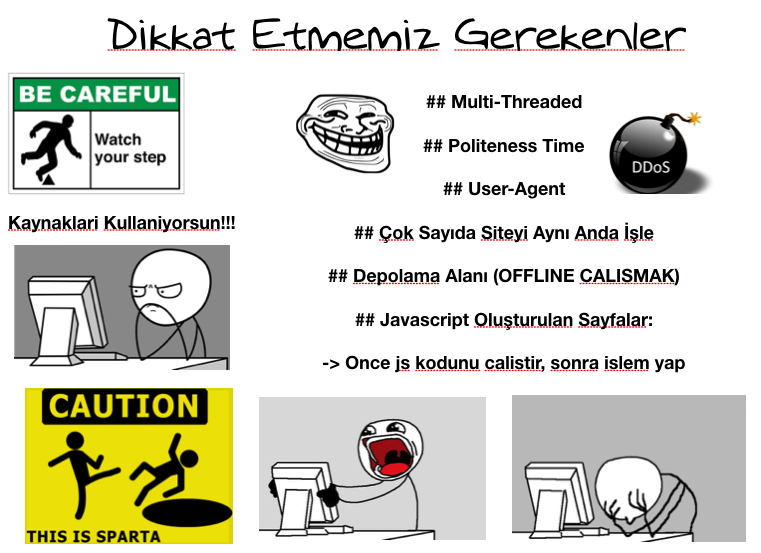
Dikkat Etmemiz Gerekenler
-
Burada ki dikkat etmemiz gereken nokta bilgi toplarken karşıda ki sistemin kaynaklarını kullanıyor olmamız. Tabi birçok site bu konularla ilgili güvenlik önemleri alıyor, hatta robots.txt içinde siteyi crawl ederken uymanız bazı kurallar bırakırlar. Zaman sınırlaması, user-agent bilgisi gibi. Ama aynı zamanda bu konu ile ilgili çok fazla case var.
-
Örneğin aynı ip adresinden belirli bir süre içinde birden fazla linke ulaşmak istemesi, User-Agent’a göre filtreleme yapma gibi…
-
Sisteminizi, crawlerınızı tasarlarken bunları göz önünde bulundurarak, sisteme saldırıyor gibi değil, insancıl zamanlarla beraber(politeness time) siteleri gezmemiz gerekmektedir.
Crawling için kullanabileceğimiz birden fazla kütüphane, framework var. Bunlardan bazılarını saymak gerekirse;
- LXML
- Selenium
- Requests
- Mechanize
- Beautiful Soup 4
- Scrapy | A Fast and Powerful Scraping and Web Crawling Framework

- Şuan için sadece Scrapy framework anlatacağım. Arada Selenium, requests ve beautifulsoup kütüphanelerine de gönderme yaparız.
Scrapy

Scrapy Nedir?
-
Scrapy nedir çok kısaca tekrar edecek olursak, web içeriklerini kolaylıkla ve hızlıca tarayabilmemizi sağlayan gelişmiş bir frameworktur diyebiliriz.
-
Şimdi sistemimize scrapy kurarak başlayalım. Python projeleri üzerinde çalışırken virtualenv oluşturmak daha iyi olacaktır. Bu makaleye özgü bir konu değil ondan direk olarak geçiyorum ama bilmiyorsanız ve öğrenmek istiyorsanız, şunları inceleyebilirsiniz. virtualenv/virtualenvwrapper
Scrapy -> https://scrapy.org/
Scrapy Tutorial -> https://docs.scrapy.org/en/latest/
Scrapy Kurulumu
- Sanal ortamımızı oluşturalım. Scrapy paketimizi python paket yöneticisi ile yükleyelim.
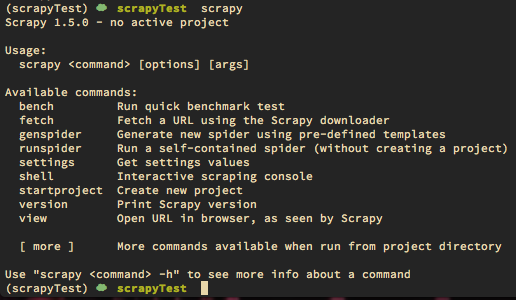
- Eğer yükleme başarılı olduysa scrapy yazdığınızda kullanabileceğiniz komutlar yukarıda ki gibi ekrana gelecektir.
- Scrapy kurduk ve artık bir proje oluşturup kodumuzu yazmamız gerekiyor. Scrapy çok geniş bir yapıya sahip olduğu için herşeyi burada anlatmamız çok güç olur. Bu yüzden bir tane web sitesi seçelim ve site üzerinde ki linkleri toplayalım.
Planlama Yapalım!!!
- Hedef siteyi belirle
- Sitenin robots.txt gözden geçir
- Scrapy komutları ile projemizi oluştur
- Modelin varsa items.py içine tanımla
- Spider oluştur
- Settings dosyasını düzenle
- Çalıştır ve dataları al.
- Şimdi böyle minimal bir planımız var. Adım adım yapmaya başlıyorum.
1. Hedef siteyi belirle -> https://example.com
2. Sitenin robots.txt gözden geçir -> https://example.com/robots.tx
3. Scrapy projesini oluştur

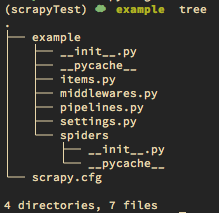
4. Modelimizi items.py içine tanımlayacağız.
- Modelden kastımız siteyi gezerken, site içerisinden alacağımız verilerin yazılacağı kolonlar gibi düşünebilirsiniz. Biz user isimlerini alalım ve aynı zamanda kaç kişiyi takip ediyorlar, kaç kişi tarafından takip ediliyorlar bilgilerini alalım. Şimdi nasıl olmuş oldu userID, following, followers .. Çıktı olarak json data istiyorum. Tabi siz farklı şekilde çıktılar alabilirsiniz. Database yazabilirsiniz, json, csv olarak alabilirsiniz gibi… Bunun içinde ayrı geliştirme yapmanız gerekiyor.
- items.py
1# -*- coding: utf-8 -*-
2
3# Define here the models for your scraped items
4#
5# See documentation in:
6# https://doc.scrapy.org/en/latest/topics/items.html
7
8import scrapy
9
10
11class ExampleItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 id = scrapy.Field()
15 userID = scrapy.Field()
16 followers = scrapy.Field()
17 following = scrapy.Field()
5. Spider oluştur.
1scrapy genspider SpiderIsmi hedefSite — template=crawl

1(scrapyTest) ☁ example ls example/spiders
2__init__.py __pycache__ example_spider.py
-
Şimdi spiderımız oluşturuldu.
-
spider dizini altında example_spider.py isminde python dosyamızı oluşturdu. Biz bunu kendimiz de oluşturabilirdik. Sadece scrapy komutlarını nasıl kullandığımızı da görmenizi istediğim için yaptım. Biz spider kodumuzu kendimize uygun şekilde yazacağız. Spider yazmadan önce miras alacağınız yapıların dökümanlarına bakmak mantıklı olacaktır. Ekstra bir iş yapmamanız açısından sizin içinde zaman kaybı olmamız olur.
Spiders Doc -> https://doc.scrapy.org/en/latest/topics/spiders.html
Spider kodumuzu yazalım
1# -*- coding: utf-8 -*-
2
3from scrapy import Request
4from scrapy.spiders import SitemapSpider
5
6from example.items import ExampleItem
7
8
9class ExampleSpiderSpider(SitemapSpider):
10 # Spider ismi -> calistirirken bu ismi kullanacagiz (settings)
11 name = 'example-spider'
12
13 allowed_domains = ['example.com']
14
15 # start_urls - Robots.txt kontrol ettikten sonra Sitemap
16 start_urls = ['http://example.com/']
17
18 # sitemap icinde belirli url ayiklamak icin rules yazalim
19 # /birseyler buldugu linkeri parse fonksiyonuna yollayacak
20 sitemap_rules = [("/birseyler", "parse")]
21
22
23 def parse(self, response):
24 # Sitenin yapisina gore parse edelim
25 # Clean url seklinde alip parse_detail isimli fonksiyona gonderelim
26
27 if 'bulunamadi' not in response.body:
28 # ... filtreler
29 # ... xpath / css / selector vs kullanimlari
30
31 for page in pages:
32 # ...
33 # callback function onemli
34 # parse_detail de istenilen datalari parse edecegiz
35 yield Request(url=response.url,
36 callback=self.parse_detail)
37
38 # Sayfa paginate mantiginda olabilir
39 next_page = response.xpath('//filtreleme')
40 if next_page:
41 # Bir sonraki sayfayi tekrardan parse kendine gonderecek
42 yield Request(response.url, callback=self.parse)
43 else:
44 return
45
46
47 def parse_detail(self, response):
48 # Modelimizi kullanalim
49 item = ExampleItem()
50 item['id'] = get_id()
51 item['userID'] = get_userID()
52 item['followers'] = get_followers()
53 item['following'] = get_following()
54 yield item
-
Burada bir prototip oluşturduk. SitemapSpider kullandık. Dokümantasyonu okuyarak amaca uygun bir yapıyı kullanmak çok önemli.
-
Biz sitemap.xml dosyasından yola çıkarak sitemap_rules içinde kuralımızı belirttik ve tüm sitemap.xml işleyerek bizim kurallarımıza göre dataları alıp, oluşturduğumuz model yapısını kullanarak dışarıya json, csv data aktarabilir yada direk olarak bir database insert edebiliriz.
-
parse_detail fonksiyonu içerisinde ki get_id() get_userID() gibi fonksiyonlar ExampleSpiderSpider class içerisinde olacaktır. Burada prototip bir uygulama yazdık. Ama pratikte yapacağınızla birebir aynı olacak.
6. Settings dosyasını düzenleyelim
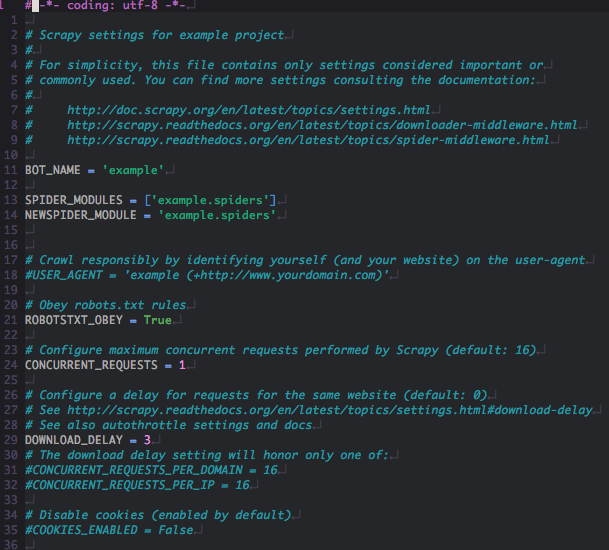
-
Settings dosyasından çok fazla ayar var.
-
Bizim için önemli olanlardan bazıları Concurrent_Requests sayımızı abartmamak. User-Agent kullanmak, Download_Delay 1–3sn arası vermek, Proxy kullanmak gibi…
Settings Doc -> https://doc.scrapy.org/en/latest/topics/settings.html
7. Çalıştır ve dataları al.
1scrapy crawl SpiderIsmi -o OutputIsmi.json

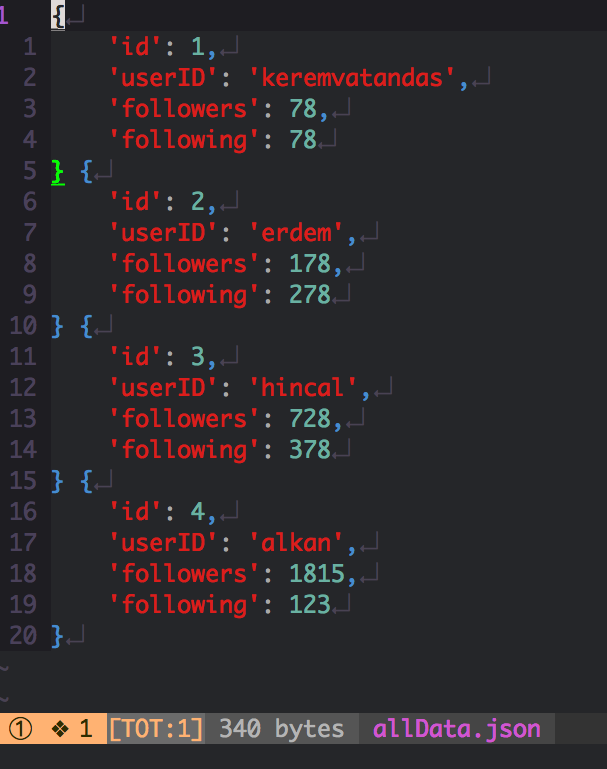
Genel olarak yapı böyle. Tabiki de bu sadece SitemapSpider kullanımı için. Dökümantasyonu okuyarak daha fazla bilgi edinebilir, crawler yazabilirsiniz. Eğer takıldığınız, sormak istediğiniz bölümler var ise sorabilirsiniz. Redis, Rethinkdb gibi entegrasyonlar yapacaksanız öncelikle pipeline kısmında bir geliştirme yapmanız gerekecektir. Daha sonra settings kısmını düzenlemeniz yetecektir. Kendiniz proxy yazacaksanız middleware dosyasının içine yazabilirsiniz. Hali hazırda çok fazla middleware yazılmış, siz bir geliştirme yapmadan önce scrapy dökümantasyonlarını okumanızı tavsiye ederim.